2022-06-29 来源: 《银行家》2021年第12期
作者:关杏元 王彦博 李晓林 张 月
随着数字化时代的来临,大数据、人工智能等精尖技术进入了高速发展阶段。然而,对一些行业而言,存在数据样本量少、特征少、标注信息缺失、数据质量差等问题,同时由于相同行业不同企业间的竞争以及同一企业中不同业务条线、业务系统间的阻隔性等情况,难以实现有效的数据信息交流与整合,易造成“数据孤岛”现象,这使大数据、人工智能相关技术难以发挥出预期的应用效果。
当前隐私与数据保护已成为全球关注的焦点,无论是机构还是个人都对隐私和数据保护越发重视,政府机构也出台了相关的法律法规来保护数据安全和隐私。而联邦学习(Federated Learning)作为一种新兴的人工智能技术,能够在隐私、安全和监管的要求下,让AI系统更加高效、准确地使用数据,突破小数据(数据样本和特征受到制约)和弱监督(数据标注信息受到制约)等条件约束,实现机器学习模型的可用性,为“数据孤岛”以及“隐私计算”问题提供了解决方案。
联邦学习的发展历程
联邦学习概念源自Google于2016年为更新Gboard系统的输入预测模型而设计的一个机器学习系统。联邦学习面向的场景是分散式多用户,每个用户客户端拥有当前用户的数据集。传统的机器学习的做法是将这些数据收集在一起,得到汇总数据集,基于汇总数据训练得到模型。联邦学习方法则是由参与方共同训练得到全局模型,首先各参与方基于自己的本地数据训练本地模型,再通过参数交换和聚合操作,得到全局模型;在该过程中,用户数据始终存储在本地,不对外发送,满足数据安全和隐私保护要求。
最初的联邦学习框架是在机器学习本身的技术层面思考信息流的传递,保护原始数据不出库。但联邦学习技术的发展,对其提出了增强安全的要求,不仅要求保护原始数据,同时要求进一步保护中间交互的参数,以此提高系统安全性。通过联邦学习结合差分隐私、同态加密、秘密分享等密码学技术的综合应用,对数据隐私实现端到端的闭环保护。此外,通过对代码、算法、通信、硬件等方面的优化,可提升联邦学习系统的性能,缩小其与传统集中式机器学习用户体验的差距。
发展至今,联邦学习技术逐渐趋于成熟,在业务场景得到了较好的尝试和应用。同时,国际和国内机构也在推动联邦学习等隐私计算技术的标准建立。例如,IEEE在2021年3月正式发布了P3652.1《联邦学习基础架构与应用指南》;3GPP、ISO、ITU-T及中国金融标准化委员会(金标委)等机构也组织制定联邦学习的相关标准,促进联邦学习技术向着更具通用性、可用性、安全性的方向发展,为联邦学习技术生态发展奠定了基础。
联邦学习的三种模式
联邦学习面向的场景是多参与方,每个参与方拥有各自的数据集。根据参与方持有数据情况的不同,联邦学习可分为三种模式:横向联邦学习(Horizontal Federated Learning)、纵向联邦学习(Vertical Federated Learning)和联邦迁移学习(Federated Transfer Learning)。
横向联邦学习
横向联邦学习是指在参与联合建模的各方之间用户重叠较少,而用户特征重叠较多的情况下,通过把各参与方的数据集按用户维度切分,并取出双方用户特征相同而用户不相同的那部分数据进行训练。
在金融场景中,横向联邦学习适用于金融机构间的联合建模,即参与方之间业务场景相似,用户特征相同,而用户群体交集较小的场景。例如,两家不同地区的银行机构,它们的用户群体相互交集很小,但是它们的业务很相似,因此用户特征是相同的;但由于某些特定业务场景,如小微企业信贷等,各参与方可使用的建模样本均较少,因而难以各自采用传统机器学习算法构建模型,在这种情况下,可以通过横向联邦学习来联合使用多个不同机构间的样本数据,扩大模型训练的样本空间,从而构建更准确、泛化能力更好的模型。
纵向联邦学习
纵向联邦学习是指在参与联合建模各方数据集的用户重叠较多,而用户特征重叠较少的情况下,通过把数据集按照特征维度切分,并取出双方用户相同而用户特征不相同的那部分数据进行训练。
纵向联邦学习往往用以解决一方数据维度过少,仅用一方数据无法较好地实现建模目标,或是一方只有Y标签,需要使用其他参与方的特征来构建联合模型的场景,多用于异业之间的联合建模。在金融场景中,纵向联邦学习常用于金融机构与其他行业机构之间的联合建模,即参与方的用户交集比较大,但各参与方所拥有的用户特征差异性大。例如,银行与运营商之间的联合建模,它们的用户交集较大,但银行记录的都是用户的收支信息、信贷行为、还款记录等金融行为信息,而运营商拥有用户短信、上网情况等通信行为信息,因此它们之间的用户特征差异性很大,银行机构在智能风控、智能营销、反欺诈、存客运营等业务场景中,均可使用纵向联邦学习,通过参与方之间特征的互补来提升模型的信息量,以增强联合模型的识别和预测能力。
联邦迁移学习
联邦迁移学习是指在参与方数据集的用户与用户特征重叠都较少,往往无法基于用户或特征进行切分,在这种情况下可以利用迁移学习来克服样本和标签不足的情况。
迁移学习的目的是把源领域的知识迁移到目标领域,使得目标领域能够跨越数据积累直接实现应用智能,通常适用于源领域数据量充足,而目标领域数据量较小的场景。例如,在金融领域的反洗钱、大额信贷业务等场景或是在业务启动阶段,普遍存在金融样本有限问题,难以采用通用的机器学习算法建模。利用源领域的大量数据训练好一个模型,通过迁移学习,将数据、模型和任务都迁移到目标领域的小数据中,可以得到一个鲁棒性较好的新模型。联邦迁移学习将迁移学习方法与多方安全计算中的同态加密等算法相结合,实现了联邦化的迁移学习算法。
基于联邦学习的隐私计算
联邦学习的基本原理是在企业、机构或终端各自数据不出本地的前提下,通过基于密码学机制下的参数交换,建立虚拟的共有模型。这个共有模型的性能经与传统方式下将各方数据汇聚在一起再使用机器学习方法训练的模型进行对比,两者效果基本一致。
联邦学习的参与方一般包括数据方、算法方、协调方、计算方、结果方、任务发起方等,这些不同角色可以根据不同的实现机制,由不同的实体承担,或是由某一实体承担多个角色。目前的联邦学习的实现架构主要分为两种:一种是基于协调方的中心化联邦架构,另一种是点对点的去中心化联邦架构。在中心化联邦架构中,各参与方需要与中心协调方或中央服务器合作完成联合训练;而在点对点的去中心化联邦架构中,各个参与方是对等关系,不存在中心化的服务器,所有交互都是参与方之间通过多方安全计算等密码协议直接进行交互和计算的。
横向联邦学习通常是基于中心化联邦架构,通过中心协调方来协调和汇总全局的模型。模型训练之前,中心协调方将初始模型分发给各参与方,各参与方再根据本地数据集进行模型训练, 然后各参与方把本地训练得到的模型参数加密上传至中心协调方,中心协调方对所有模型梯度进行聚合,再将聚合后的全局模型参数加密传回给各参与方,反复此步骤,直到全局模型收敛得到最优模型。而纵向联邦学习根据不同业务场景、参与方之间的信任度、安全强度需求等,可选择采用中心化联邦架构或去中心化的点对点网络架构,与之对应的是采用密码学技术的差异。联邦学习常采用同态加密、差分隐私以及秘密共享、不经意传输、混淆电路等多方安全计算技术来增强中间交互模型参数的安全性。此外,随着产业应用的需求,联邦学习也与其他多元技术融合来满足更多应用场景。例如,通过采用差分隐私进一步增强对梯度参数的保护程度,防止中间梯度信息的泄漏与原始数据的反推;与可信执行环境融合,进一步提升本地隐私数据的安全性或模型的安全等级。
联邦学习的金融应用场景
反欺诈场景
机器学习在金融反欺诈的应用场景中迅速发展,并已取得显著成效,金融诈骗行为能够被有效识别。但在巨大的经济利益驱动下,金融诈骗手段层出不穷,传统基于单一企业的数据建模逐渐难以应对不断升级的诈骗手段,需要通过联邦学习等隐私计算技术打通企业间的数据孤岛,构建跨行业数据共享的反欺诈模型,以提升金融反欺诈的效率与精准性。
借助联邦学习技术,可以在保证用户隐私信息、企业的数据安全以及企业的数据所有权与控制权的前提下,融合银行机构、电商、运营商、政务等多元数据,实现跨行业、跨机构的反欺诈体系建设。基于金融行为特征、消费行为特征、通信行为特征、社交行为特征等,构建针对不同细分金融反欺诈业务场景的专有模型,通过跨行业、跨机构的多样性欺诈数据特征互补,从而提升金融行业的整体反欺诈能力。
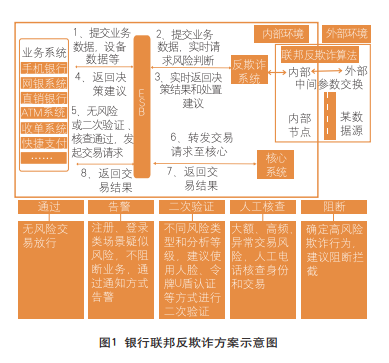
以国内某商业银行为例,其借助联邦学习技术,引入外部数据源,联合行内已有样本和特征,利用联邦Fastboost算法构建反欺诈模型,并与现有欺诈系统进行对接,具体应用如图1所示。
实证结果表明,通过联邦学习算法构建的跨机构反欺诈模型, 其AUC指标达到0.84,KS指标达到0.55,KS指标对比仅基于行内数据构建的模型提升了约15%。这表明联邦学习模型能够对用户欺诈行为进行有效识别,有效提升商业银行的风险防控能力。
信贷风控场景
在信贷风控领域,因信审过程需要调用不同的数据接口,因此面临着信贷审核成本高昂的情况;此外,银行等金融机构在面对中小微企业的信贷需求时,缺乏企业经营情况等有效数据,导致中小微企业融资难、融资贵、融资慢;同样,消费金融类企业在面对风控时,缺乏互联网用户行为画像等有效数据。
在中小微企业信贷场景中,针对中小微企业信贷评审数据稀缺、不全面、历史信息沉淀不足等问题,通过联邦学习机制,在确保数据提供方数据安全以及隐私保护的情况下,能够为银行融汇企业经营数据、税务数据、工商数据、支付数据等多源信息,丰富建模特征体系,共同提升模型的有效性。此外,通过将风险前置,从风险源头切入,采用隐私计算还可帮助金融机构过滤信贷黑名单客户以及过滤明显没有转化价值的贷款客户。
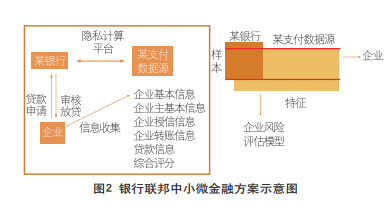
以国内某商业银行为例,其在进军中小微企业贷款市场过程中,苦于没有充足的数据特征维度用以判断企业的信用评分,因此将风控缩紧,虽然保证了业务安全性,却降低了盈利性。借助联邦学习的方式,该银行与某支付机构进行跨机构数据协作,对企业进行信用评估。银行提供建模样本Y标签,外部合作机构提供相关样本的X数据特征,采用联邦逻辑回归算法构建风险评分模型,对客户进行评分区间预测,相关方案如图2所示。
基于外部数据源辅助的模型训练结果显示,其AUC指标达到0.71,KS指标达到0.34,能够为银行在中小微信贷场景提供有效的风控能力。
此外,联邦学习技术也可用于消费金融机构信贷场景。针对消费金融机构Y样本量不足、好坏样本区分度不够、样本呈偏态分布等问题,建议通过联邦学习机制,融合多家信贷机构的数据进行小样本联合建模,并不断积累业务数据迭代优化模型。
银保营销场景
银行在保险业务的推广方面存在天然优势,同时也是其重要业务组成的一部分,但是目前银行在保险产品的营销和精准获客方面存在以下的问题:一是获客难度大。银行在寻找客户过程中,因客户画像不精准,导致获客转化率低。二是客户需求把握不准。因客户维度的缺失,导致银行营销人员对潜在客户的需求定位不清晰,难以挖掘其真实需求,潜在价值没有得到充分的发挥。三是总成本居高不下。因获客转化率低,同时产品推介针对性不强,导致银行保险业务营销的整体ROI偏低。
以国内某商业银行为例,在代销保险业务中银行希望从数亿客群中挖掘出潜在的保险用户,进行银保交叉营销。在实施过程中,采用联邦学习技术,利用保险公司已有人群特征标签作为种子用户,并选用联邦推荐算法,构建多维、准确的联邦推荐模型,从而识别出更多潜在相似人群,同时优化营销渠道。
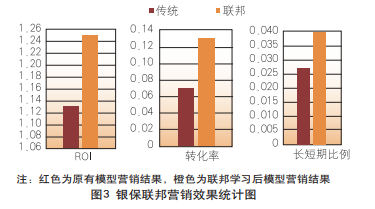
对模型运行结果及营销结果进行统计分析,实证结果表明, 在转化率、ROI、长短期保险营销比例等方面,联邦学习模型结果均有较为明显的提升,如图3所示。
结语
联邦学习是当前隐私立法时代能够兼顾隐私与数据保护要求以及机器学习、数据挖掘应用需求的一项前沿IT技术。在商业银行具体业务场景中,基于联邦学习的隐私计算平台能够解决数据使用合法合规的问题,拓宽金融行业数据边界,并打破数据割裂的壁垒。借助联邦建模可以在保护用户信息不泄露的前提下,将来自支付应用的消费数据、交通出行数据、通信数据、上网行为数据等多方、多维度信息纳入联邦风控模型、联邦反欺诈模型、联邦营销模型、联邦反洗钱模型等多类业务场景中,在满足合规经营的前提下,进一步推动银行数字化转型、智能化发展,全面提升商业银行的业务质效。
(龙盈智达〔北京〕科技有限公司大数据中心杨璇、袁开蓉以及同盾科技有限公司人工智能研究院彭宇翔、张明明对本文亦有贡献。王彦博〔wangyanbo@lyzdfintech.com〕为本文通信作者)
(作者单位:华夏银行股份有限公司信息科技部,龙盈智达〔北京〕科技有限公司,同盾科技有限公司人工智能研究院)
责任编辑:魏敏倩
公众号

微信扫码关注
微博

微博扫码关注